The Surprising Effectiveness of Test-Time Training for Abstract Reasoning 论文复现报告(二):实验报告States 论文阅读报告
前言
第一部分的实验还是挺多的,也是一个熟悉微调大模型的好机会,总之先开始吧
正文
第一个实验:用无TTT结构的微调模型跑实验
具体参数:
模型:llama3-8B(微调版本)
数据:419个问题(来自ARC和增强数据)
设备:A100-pcie-40gb
操作步骤
- 首先用作者给出的微调模型跑一下实验
- 记录实验结果
实验结果
- 第一次:

- 第二次:
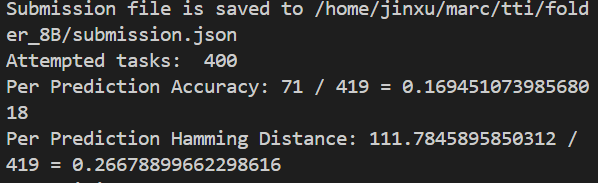
这里贴一下对于400和419的理解:
关于 419
来源及含义:
从代码中可以看到args.num_examples参数的默认值被设置为419,其代表的含义是用于限制处理的任务数量。也就是通过read_tasks_from_single_file函数从指定的数据文件(args.data_file)读取任务后,会对任务列表进行操作,如果args.num_examples有值(这里默认就是419),会截取任务列表的前419个任务来参与后续一系列的处理流程,例如预处理、生成输入给模型的查询、进行预测以及后续的评估等操作。所以这个419体现的是最初设定要参与处理的任务数量上限(当然,如果实际数据文件里任务总数不足419个,那就是实际的任务数量)。
在准确率计算中的体现:
在 “Per Prediction Accuracy: 42 / 419 = 0.10023866348448687” 这一计算中,分母使用419就是基于上述设定。表示在所有设定要参与处理的这419个任务里,统计预测准确的任务数量占总任务数量(也就是419个)的比例,以此来衡量预测准确率情况。
关于 400
来源及含义:
400这个数字出现在 “Attempted tasks: 400” 和 “Competition Accuracy: 40 / 400 = 0.1” 中。结合代码逻辑来看,经过前面一系列的任务预处理、筛选(例如根据任务是否有效等条件筛选,像在get_preprocessed_tasks函数执行后区分出valid_tasks和invalid_tasks)、生成输入给模型的查询等操作后,最终实际真正去进行后续核心处理(比如将输入给到模型进行预测等相关操作)的任务数量是400个。也就是说,虽然一开始设定要处理419个任务,但由于部分任务可能因为不符合某些条件(比如预处理后无效、相关查询生成不符合要求等原因)被排除掉了,剩下400个任务进入到后续进一步的预测、评估等环节,这里的400体现的是实际参与后续关键处理流程的有效任务数量。
在准确率计算中的体现:
在 “Competition Accuracy: 40 / 400 = 0.1” 这一计算中,分母使用400就是基于上述实际参与后续关键流程的任务数量情况。即统计在这400个实际尝试进行处理(如预测等操作)的任务里,达到竞争准确率评判标准(具体评判标准应该和竞赛相关要求有关,代码中通过evaluate等函数实现相应评估逻辑)的任务数量占400个任务的比例,以此来衡量竞争准确率情况。
综上所述,419 是最初设定参与处理的任务数量上限,而 400 则是经过前面多轮筛选、处理后实际参与后续关键流程的任务数量,它们在不同的准确率等评估指标计算中分别作为分母,来体现对应不同阶段和不同评判标准下的任务相关统计情况。
第二个实验:用TTT结构正常跑一次(8B,3B,1B)
具体参数:
模型:llama3-8B(微调版本),llama3.2-1B,llama3.2-3B
数据:419个问题(来自ARC和增强数据)
设备:A100-pcie-40gb
训练轮数:2
batch_size:1(8B),2(3B),3(1B)
操作步骤
- 首先训练
- 然后逐个推理
- 记录实验结果
实验结果
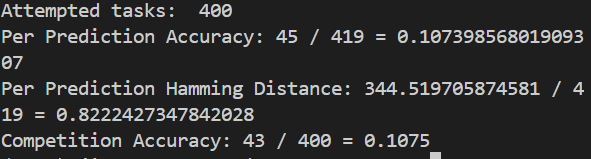
- 8B:
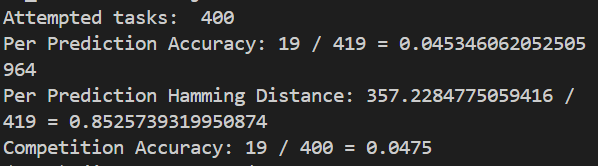
- 3B:
- 1B:
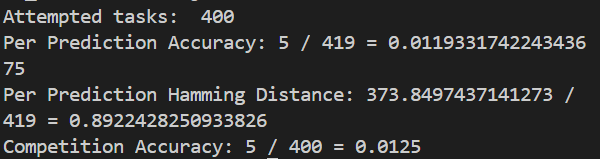
这里实际上看得出来随着模型的参数变大,准确率也在上升
第三个实验:使用标准推理方法,不进行任何增强推理操作
具体参数:
模型:llama3-8B(微调版本)
数据:419个问题(来自ARC和增强数据)
设备:A100-pcie-40gb
操作步骤:
- 修改代码,主要修改部分:
 改成:
改成: 显然,主要是把这几个数据增强手段给删了
显然,主要是把这几个数据增强手段给删了 - 针对修改写新的脚本,执行即可
结果
- 第一次:

2.第二次:
可以看出来,掉了一些点
第四个实验:评估单个几何变换(旋转、转置、翻转等)在推理过程中的单独有效性
具体参数:
模型:llama3-8B(微调版本)
数据:419个问题(来自ARC和增强数据)
设备:A100-pcie-40gb
操作步骤:
- 修改代码,主要修改部分:改成:
 ,
, 等等,显然,主要是把这几个数据增强手段给进行单独保留
等等,显然,主要是把这几个数据增强手段给进行单独保留 - 针对修改写新的脚本,执行即可
结果
- 旋转90度:

- tranpose:

- Flip1:

- Flip0:

后记
该写ppt啦